Transaction log is not just any log
For those who are finding out this the hard way, this little post might just shed some light.
So if you have somehow deleted or lost your transaction log for a database in SQL Server, this will come in hand:
ALTER DATABASE DBName SET EMERGENCY;
GO
ALTER DATABASE DBName SET SINGLE_USER;
GO
DBCC CHECKDB (DBName, REPAIR_ALLOW_DATA_LOSS)
WITH NO_INFOMSGS, ALL_ERRORMSGS;
GO
Mind some buzzwords here, especially the one that says: “Allow data loss”. Because that’s what will happen. Yet, don’t be afraid – most of the transactions are commited anyway, so the loss won’t be that big.
ALTER DATABASE DBName SET MULTI_USER;
Don’t forget to change to multi user for regular usage.
Trolled by a banklink
A consulting client approached me today, asking about some problems. Well it was eyebrow-raising, so to speak.
Apparently banklinks in the UK (specifically – Worldpay) let you pay for goods using credit and debit cards, easily. You are like card number and pin away from spending whatever the amount the card holds. No names, surnames, addresses or anything like that is verified. Hence, people are using stolen card info to buy stuff (who would’ve thought). Then the service provider ships out the stuff, or provides the services. Few weeks after that – the payment is rolled back, because of the reported theft. The owner got his money back, the thief got the goods and the provider has neither goods nor money.
So, long story short, my client asks me, how do you deal with this in Lithuania? Wait, what. There are no such problems, because paying on the internet via cards is only marginally available. Like 1% of the shops has it. Personally I have never seen it, yet I suspect they exist. Everyone uses electronic banking services and banklink basically fast forwards you to your banks system.
Wow, replied the client, that’s like 5 steps forward already. We only recently stopped using checks by the way.
Checks? Seriously?
Microsoft sadness
Microsoft is doing a lot to improve itself, yet, from time to time, they give me enormous amount of sadness. It comes from small things, once again proving that devil is in the details.
So, I was trying to use NuGet on my MVC3 application to get some packages: to setup MiniProfiler all you need is 2-3 packages. So the main installed smoothly, and the second one told me that my NuGet is out of date (I was still somehow using 1.2).
Fair enough. So I download and install NuGet 1.6.
2013.02.11 10:55:38 – VSIXInstaller.SignatureMismatchException: The signature on the update version of ‘NuGet Package Manager’ does not match the signature on the installed version. Therefore, Extension Manager cannot install the update.
Whatever that is I google it and come up with two possible solutions:
- Remove old NuGet and install fresh
- Apply a patch KB2581019
As the first option got me nowhere, I tried doing the second one:
http://connect.microsoft.com/VisualStudio/Downloads/DownloadDetails.aspx?DownloadID=38654 this is the download page for that hotfix, seems that metro redesign wave skipped this one.
This web page starts very crazy stuff: it offers you to download the patch using File Transfer Manager (kinda reminds me of megaupload kind of sites which all offer their spyware-included download managers) and yes – this download button doesn’t work on Chrome.
Well, I’m patient: I open IE10 (which is nice by the way), launch this same page and install the Microsoft File Transfer Manager. First thing it does is offer me this:

You might guess what was my choice from the dashed line on the cancel button.

The UI is more or less back in Windows 98 (see the buttons with the arrows!)

After downloading, validating and whatever the thing else has taken around ~5 minutes we also have to install it and this just hangs in there for few minutes more without any progress. Yet suddenly:
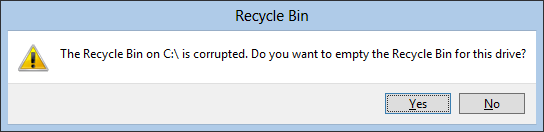
Well, ok – while we’re at itė (or whatever) we can of course fix my recycle bin.
 Don’t be fooled by this great success – you will also have to restart the Visual Studio before using NuGet.
Don’t be fooled by this great success – you will also have to restart the Visual Studio before using NuGet.
I mean, yeah, this took me about 30 minutes to figure out, which is not that much, since the blog post also took me 10-15, but still I’m having second thoughts about owning Microsoft stock 🙂
Paying off your technical debt
Yeah, right, another blog post about technical debt. A lot of (and I mean, maybe, thousands) bloggers before me had written on technical debt, a term coined by Ward Cunnigham. Heck it even has a wikipedia page: http://en.wikipedia.org/wiki/Technical_debt
So after all has been said and done… wait. Yeah, exactly, nothing has been done – everything was said, in the form of bitchy-angry blog posts and nothing much has actually being done in the form of concentrating and solving stuff, paying off, doing things right.
The thing is, that most of the time developers learn about technical debt when they pretty much have too much of it or they jump into a project where there is a lot aquired before them. Further extending the analogy it could be either an oblivious cocaine-driven business model or an investor who buys a pretty looking company which is not exactly what the salesman tells it is. In the first case, developers were hell bent on delivering features, on time, on budget, cutting corners was an option and every corner was cut without much consideration. Or they were forced to deliver whatever the impossible-to-meet deadline was implying them to deliver. On the other case you pretty much have this same company five years later. Over-worked and under-staffed now they are and stuff is not going well.
By looking over the business data (think: bottom line, turnover, etc.), you might say that sales are down or investment has stopped or whatever it is that business data can tell you. In IT companies it comes down to this. If you have a product, and someone is interested in it, or buying it, or investing into it. If you have no ability to scale up, move fast andor adapt it, it is going to fail very quickly. Considering the amount of startups, doing a lot of really cool (though, sometimes, really simple) stuff it is easy to say that moving as fast as they go (if not faster) is something of an objective. If you have motivated, smart people – this is not a problem. Unless you have a lot of technical debt.
Ok, let’s go there – agile methodologies do not address this at all. I mean seriously, there is nothing there about it neither in scrum, nor kanban, nor DSDM. Ok neither there is something about it on waterfall, but that’s like a totally different subject. Basically, it comes down to this – developer (or the whole team) estimates a task and plans it, but they do not take into account the technical debt that the product has. A primitive example:
As a sales manager I want to see how much sales has a client generated per month
Good for you mr. sales manager, although you might not know that we only have one table column about that client ant it only contains a total sum of client generated sales. So to split it we have to produce another structure for sales with amount and dates, and it might take a while for you to get the right data. And bam, here is the pitfall: because of the generated technical debt, where it is only logical to have the data split by exact dates we have encountered a some kind of shortcut that was made by someone, some time ago. Yet, no one has estimated this and yet the client won’t be happy when he gets something expecting to be something that he asked for – he could not go into 2 years ago (when he started using and paying for your product) and see some of his clients data, because there is no way to present him to it.
So again, coming back to paying it off. It really breaks down to something as simple as paying a real debt (yeah, right, easy):
- Know how deep you are. Ask everyone on the team and anyone on the product, even if in any other team, what needs to be done to make it right, bug free, rock solid.
- Collect this advice and sort it out. You will need great wisdom to do this, since a lot of developers will be pushing you some new concepts, of how they imagine it would be good to do it or some new technologies they are excited about, while the old ones work just fine and will work for the foreseeable future.
- When you are very deep in a hole (you didn’t expect you don’t have any debt at all, did you?) – stop digging. Stop aquiring new debts along the way, which are going to get you even deeper.
- If you have the resources to pay it off instantly – do it. No more questions asked. If you have 20 mandays of technical debt in your product and 2 developers with nothing very important to do for 10 days, that should be your first priority.
- Otherwise, you have to build a plan, to get back on top.
Now this unknown state of having no technical debt should include such basic things as:
- You are basically bug-free. There are no software without bugs, yet those that are present in your product are so minor that you don’t even bother to report them.
- You can release anytime you want. Your product is stable or the new features can be stabilised in a day or two. This should be achieved by aggresive coverage of automated tests and overall quality of the code, decoupling, solid principles, etc.
- You can move fast and you can implement anything without a lot of deviations from the original estimate.
This state is every managers dream and it is that solid foundation on which you can evolve the product. Yet it is unreachable until you deal with your debt. So start paying your dues, the sooner the better.
DevOps reactions
I’m not exactly in dev ops but being a frontend developer who basically has a backend in the form of WCF services, I can relate to most of these memes:
http://devopsreactions.tumblr.com
Any developer in cloud business will relate as well 🙂
Performance in the cloud: Javascript overview
JavaScript has became the ultimate technology in backend of our frontend. Web application UI is powered and becomes interactive mostly because of it.
A lot of great frameworks (jQuery, knockout.js/backbone.js, prototype, backbone) emerged on making things easy. Easy creation draws attention and more and more things are done in the easy-creation field (if that is to be disputed, one should compare the activity in StackOverflow on such tags like php, javascript, jquery and then on t-sql, c, regex, etc.). That is all great until it starts falling apart. Many people writing code by samples, copy pasting it putting up things together that “works”. Well yeah, until you have to extend and maintain it. Or as we sometimes have to do: make it work on that machine. That machine usually is old, has old windows, old Internet Explorer and so on.
We had this application – a mashup of technologies: jQuery, jQuery UI, some silly treeview plugin, A LOT OF our own code, helpers, implementations, loaders, somewhere classes, somewhere functions. Well you know – your typically “I rather just throw it all out” situation. Things were running OK on quad core CPU’s, stuffed with gigabytes of RAM.
And then came the go live. We had few busy weeks of late-night refactoring and performance tuning of JavaScript – one thing I thought I will never have to do (because it just works you know).
So really simple lessons learned and things to take into consideration when dealing with it.
Cache selectors
$(‘.class1:not(.class2) > input[type=text]’).val(‘because you can do this doesnt mean you should’);
$(‘.class1:not(.class2) > input[type=text]’).attr(‘disabled’, true);
This selector is bad. It tells a lot about your HTML/CSS structure (that you have none) and the fuzzy logic you are doing here. But still, if you need this kind of selector more than once, cache it.
var selector=’.class1:not(.class2) > input[type=text]’;
$(selector).val(‘because you can do this doesnt mean you should’);
$(selector).attr(‘disabled’, true);
I shit you not, this was a selector caching idea of one of my senior colleagues (too many coffees and too little sleep I guess).
var $selector=$(‘.class1:not(.class2) > input[type=text]’);
$selector.val(‘because you can do this doesnt mean you should’);
$selector.attr(‘disabled’, true);
I like to prepend jQuery variables with $, so to not get them confused. Anyway, this simple step does not only increase the performance twice, but also supports don’t repeat yourself principle (yay). Note here: it’s ok to use chaining, since the selector is reused, but it’s not always possible or good enough:
- There are things that you need to do in between the manipulation of selected objects.
- Different functions/classes can reuse the same selector which is cached somewhere in the beggining of pageload and never invalidated throughout the pages lifecycle.
Another thing to cover here is $(document).ready() or $(window).load() (surprise surprise). These functions became the location of all the initializers and basically all the code there is to execute on page. The important thing to remember is that when you write:
$(document).ready(function () {
$(“.someSelector”).on(“click”, ….
It doesn’t do anything until you click it – yes, except for the selector part. And if you don’t have any elements on that selector than binding on the click event is more or less useless. Sometimes you include a lot of stuff in the ready/load function, despite that it is not used on all pages and doing so hits your performance badly because of the selector that are executed everytime.
$(document).ready(function () {
$(“.communications .field input[type=’text’]”).on(“change”, function (ev) {
If you have something as complex as the example above it is wise to check whether there are actually element of class “communications” before doing anything else. The selector gets heavier with eash and every level you add:
$(document).ready(function () {
if($(“.communications”).length>0){
$(“.communications .field input[type=’text’]”).live(“change”, function (ev) {
Doing something like this will help a lot. This could be true to a lot of other cases, perform selectors and logic only if the things you are doing it with rendered. So adding more check is relatively reasonable – relatively, because if your selector is as as complex as your checking selector, well then it will do you no good.
This also brings us to another point about having most of the stuff in ready/load functions and keeping it together or keeping it separately in several different files. Doing multiple browser requests to a non-CDN hosts can be a performance issue as well as loading one big file with a lot of logic dedicated to different things. Also maintenance is something of an issue in the later approach. I would advocate for the approach of doing multiple requests and adding a HTML5 manifest cache to the application. This way all of the used JavaScript files are pre-loaded to the browsers cache and can be used with little overhead. The tricky part, of course[1], is cache invalidation but it can be dealt by tuning your deployment process to change a comment line in the manifest file, so every new version will have a different cache – yet it will be valid per version.
One should use databinding instead of loading partial views. Partial views are great and easy way to achieve a lot of things in ASP.NET MVC. The use of unobtrusive ajax and all great features adapted to it in the framework, makes life easy for more of HTML centric application approach. But once it shifts to JavaScript – beware. Partial loads containing JavaScript can make a great impact on the running performance, since the partial view is loaded, the DOM is manipulated and the new JavaScript is evaluated. While working with REST services or generally a more JavaScript based applications, it is relevant to switch to JavaScript binding, and since that is also common to see in WPF apps – it doesn’t get much less microsoftish.
Lastly, a mention about setTimeout, setInterval and eval is in place. Whenever using setTimeout/setInterval, use functions instead of strings, because strings invoke the compiler. Basically what you do is eval the string and that hurts, hurts a lot. So the same goes for eval.
So instead of:
setTimeout(“foo()”, 1000);
use:
setTimeout(foo, 1000);
A note has to be added on the toolbox that can be used to determine what is performing badly. Every major browser has it’s developer tools and performance profiling of scripts is included.
Internet Explorer 10 shows only a basic overview though:

And Google Chrome has it more in-depth:

Letting you check not only the CPU usage of JavaScript, but also the quality and impact of CSS selectors and also the memory usage.
This is the first post in the bigger series – the next one will be on web application performance inspection, so each step will be deeper in the clouds.
[1] – There are only two hard things in Computer Science: cache invalidation and naming things. — Phil Karlton
Knockout.js to seriously knock everything out of your way with JavaScript
Coming from “microsoftish” programming background, while also supporting, updating legacy software, it is often hard to keep up with all the new ways of programming, new frameworks and technologies around. So last month we were doing our periodical technical debt pay-off regimen which came up with some new ways of doing things. New for us, of course – sort of a local innovation.
A while ago there was jQuery template, but then it was abandoned and so a lot of people moved on to other things. Some tried to reinvent the wheel by making their own template engines, others moved to solutions like Unobtrusive ajax. I myself was a big fan of this technology, you basically do not load json, rather you use partial views, render parts of HTML code.
Now partial views and unobtrusive ajax are nice technologies. If you are making simple websites, any kind of simple stuff:
<form action="/ajax/callback" data-ajax="true" data-ajax-loading="#loading" data-ajax-mode="replace" data-ajax-update="#updateme" method="post" >
Here we see that a form is posted and the result is rendered in the element that has ID – updateme. It is all great, but what if you have to update more then one element? Off course you can add “data-ajax-success” atribute and execute custom JavaScript there (or function call perhaps). So here you go it started sucking as soon as you did something not under the intended use but still quite common. So we used this approach for a while, violating any normal development principles that are out there. And apparently it worked for some time, until the logic got way more complex – it still works now, but we have a lot of common issues for this situation. That is hard to maintain code, unstable code which breaks after changes on one end.
So time came to change things and we were looking for some templating engines, things that normalize the JavaScript code and make it readable, maintanable and stable. And we came across this awesome framework: Knockout.js
Simple things that can be learned from the tutorial:
- You have templating
- You have JSON data binding
- You have readable code
- It performs well
- It is extendable
The first thing I went to is the interactive tutorial and I can say, without doubt, that these are the best tutorials I’ve ever came across – try yourself and you will see. Even if you had no coding experience before, they are crystal clear!
Let’s stop for a minute there because I see myself getting over-excited and I maybe even translated some of that excitement to you. All new technologies are great, but as I mentioned in my last post – they are meant to solve problems and you have to be sure (or at least positive), that any technology will solve you your problems before using it. That is, indeed, a conservative way of thinking. Yet it also corelates a lot with business thinking: there are times when management is too busy to interfere with technology and there is no R&D department and no one is telling no one to invest into new stuff. Even more: it seems like everyone is trying to stop innovation from happening because everytime you go to your boss with an idea like that “oh hey, let’s rewrite our all frontend with this” you’ll get a response:

The manager is defensive, he knows that it will cost money and the benefit – well you mentioned none. So first of all get all your arguments straight, business people like when you offer them to solve their problems. Yet, rewriting everything from scratch is not a good idea afterall (read – http://www.joelonsoftware.com/articles/fog0000000069.html) unless it really really solves your problems or reduces your technical debt, which must be tracked as well. Not that it does that by letting you mess with some pieces of new technology, but basically covers a list of specific problems (even tasks), that you can clearly write down as a list.
So coming back to knockout.js – let’s define the problems we are solving and see how knockout.js fits here:
- We need to have configurable grids in multiple places on our frontend
- The grids have to be not only configurable, but of course have the basic functionality of all the grids as we know it: headers, rows, sorting, paging
- We need to display action buttons on specific events
- We need to remove our overhead of mapping and handle DTOs in the client side
- We need to expose JSON endpoints for some other parts of our product (mobile apps, office addins, etc.)
- We are seeing an impact on rendering performance done by partial view rendering and need better solutions
- We have few bugs that could be solved by implementing all of the above
This is list is of course generalised, because no one wants to go in deep into our product problems (trust me, you don’t want it).
So, I’ve been researching it for a few days, those days have of course spanned through out the holidays, so here are the results.
We need to have configurable grids in multiple places on our frontend
To solve this we basically have to get a few collections in our JSON data, one with the columns and another one with the data, and everything after that goes splendidly with few foreach loops:
<table border=”1″>
<thead>
<tr data-bind=”foreach: gridColumns”>
<th data-bind=”text: $data.title”></th>
</tr>
</thead>
<tbody data-bind=”foreach: gridItems”>
<tr data-bind=”foreach: $root.gridColumns”>
<td data-bind=”html: $parent[$data.name()]”></td>
</tr>
</tbody>
</table>
You can check out the full working fiddle here: http://jsfiddle.net/povilas/4FXxd/
Note here, that columns are intended to be persisted in the backend (a.k.a. the cloud), so taking that in mind, there is no need for instant GUI refresh after column hides and so on, you could just reload the data with the different configuration of the columns. One could change the booleans in the jsonData variable to change that accordingly.
Now look at that – how many nice points have we covered: this is a normal configurable grid, which can be parametrized and has minimum possible JavaScript footprint ever imaginable. This doesn’t even remotely compare to what any OOTB grid components are trying to give you. Sure you get a lot of prebuilt features, but you have to learn some third party constructs, parameter sets, modify your backend accordingly and later on having to maintain all of its possibly crappy implementations and uncovered bugs. Here you have pure JS + HTML code, rendered really fast.
I must confess here, I haven’t done any real performance benchmarking to compare numbers, this time it was based on some simple logics: let’s not do the same thing we have tried to do the last few times (use third-party grid components). Everytime we tried that approach it got us nowhere near what we wanted: on old PC’s – performance was good when there were 20 rows with 5 columns. But when it got to 200 rows with 40 columns, it got out of hand. Yet, the heavy weight libraries of JavaScript didn’t played well on slow connections as well. Knockout.js weights merely 40kb minified and provides us with a totally new approach to build our apps.
This first fiddle already solved the 1st and 6th problem, provided a good start for the 2nd. Yet it didn’t demonstrate on how we are going to bind on different actions (3rd problem):
http://jsfiddle.net/povilas/GFEJK/
Here we also use observableArray to inject it with the object ID’s which can be later used in actions.
This usage of technology, solving the defined problems has given the programmer arguments to invest more time into it, since it is now not only technologically but also economically reasonable – it pays off, and that is what your manager wants to hear.
Thoughts on building metro apps
Today was a workshop at Microsoft Lithuania HQ about how to build metro apps with HTML5 and JavaScript.

It was a really fun and productive day with a lot of cookies, coffee and code. Not to mention really bright people that came to learn.
Contrary to the popular belief – heard it from various developers in various levels and work areas – JavaScript and HTML5 based apps are not compiled or transformed in any way to the regular C#/XAML apps. Rather they use a Internet Explorer 10 engine to render everything and everything you code is run as-is. This has some awkward drawbacks but also proves one thing straight: that IE is finally efficient, modern browser capable of doing lots of stuff, providing all necessary API’s (even IndexedDB) for cutting edge web and, as learnt today, application developement. This also means that you can easily incorporate any JavaScript framework you like, ranging from jQuery, jQuery UI/mobile/plugins, knockout.js, backbone.js, like whatever floats your goat.
One important thing here is that this should not be compared to HTML5 implementations of apps in other platforms (Android, iOS, BlackBerry). There it is actually converted to the native code and the troubling factor is that doing so hits your performance real bad. Apps made with HTML5 don’t feel as smooth, they lack the intended awesomeness of native apps. Hence, HTML5/JS tandem is merely a tool for prototyping and quick demo building or an app that you must build cross-platform ASAP (see Titanium SDK, etc.). But when you decide to do quality things right you need to switch to the native code (so Objective-C or JAVA). It is a big advantage here that it is not the case here. You won’t experience any slugishness or other unitended consequences when choosing HTML5/JS over C#/XAML, you will have the same – if not better – performance results and quality.
Now on to the awkward drawbacks: you cannot use TypeScript in your project. http://www.typescriptlang.org/ – just look how very nice and metro this website looks! It provides the type safety and other features, that some say are missing from native Javascript. The TypeScript compiler compiles/transforms TypeScript code into native JavaScript that can be later used in websites. This is a real fetish for Microsoft based developers that call <table> – a grid component and a absolutely positioned <div> – a dialog component. They have the urge for stuff to be compiled, they need type safety because they think it is safer, cleaner and so on. You might get the feeling that I’m don’t like any of those things, but the truth is I’m someone in the middle. While not seeing how type safety can benefit anyone in the web development, the benefits in business intelligence, heavy data processing – well all kinds of enterprise software – are crystal clear. Coming back to the TypeScript incompatibility in metro apps we see a big corporations failure in communication when doing a lot of things fast. Well that is a thing hard to achieve, but the situation gets just plain silly when you have one team of Microsoft evangelising TypeScript as the companies way to do stuff with JavaScript, by adding features to it and telling us how to do things. Yet another team is telling us how to program apps for their platform in JavaScript and it does not support the stuff you should be doing according to the TypeScript people. Note here: it is possible to use TypeScript, but you have to compile and then add the compiled JavaScript to your app.

The overall development of apps look quite simple and well thought-through. One can claim that Microsoft is taking the approach that Apple took a while ago. Our lecturer Stepan Bechynsky was excelent at stressing what we can and cannot do with metro apps. For example there are fixed number of tile layouts of the apps. And you cannot customize them or add anything new. Everything you will ever need is put on the plate and you must use it because that is the convention and that is the guideline. There is finally no such thing as an analyst designing UI or making stuff up that he thinks is comfortable or usable. This arrogant approach is common practice in many many development organizations. Some people might advocate that this approach limits their creativity and freedom to do whatever they like, but actually, simply put, it protects them from their overrated “competences”, over-though, over-complex ideas and puts it into a solid framework where you build from basic parts, which have defined shapes and other basic features. For example a simple idea – to play a video in a tile, or to have smaller font in one of the templates – would violate the continuity of the metro environment and eventually things would start to get messy.
Being all nice-looking and really usable metro apps have not much to offer to institutional clients, big business or governments. The most common and the only worth noticing case of such implementation is executive summary kind of dashboard. Where a manager sees the overview of his subordinates, tasks, budgets, project deadlines, bottom lines, etc. So basically we could have a metro app for a working ERP, DMS, CRM system that shows some reports, charts, maybe allows to make decisions, delegate tasks. The scarcity of ideas in this sphere shows, that the environment is indeed young, undeveloped and promising a lot of big opportunities, new ideas and ways to change peoples habits.
That could be supported by the fact that everything is very very “cloudy”. You basically are encouraged to use Windows Azure or other cloud services. The thing here is that you have no much ways to deal with this any other way. You have no backend in HTML5/JS and most likely you will obtain any data from a service and services tend to reside in the cloud.
Another notable thing is about licensing and app store approvals. Apple has a bit different approach – you have the mobile market which covers tab and phone apps and you have the dekstop market which covers Mac OS apps. Here you have Windows market which covers Windows 8 and Windows RT so desktops and tablets are covered and you have the Windows Phone which covers phones. The price for developer license is 49$ for Windows and a hundred for Windows Phone. Now, make no mistake here blaming Microsoft for not having a unified license, because you actually get something for your fee here. That is actually quality assurance: you need to pass a certification for your app to comply with the requirements. This way Microsoft helps you test your app and identify its weaknesses, find bugs, common issues and it also keeps the store clean of crappy software. And this process is done well, although sometimes could be very subjective:
1. Windows Store apps provide value to the customer
1.1 Your app must offer customers unique, creative value or utility in all the languages and markets that it supports
This indicates that the app must provide “creative value” which is a very abstract term. The given example was about an app “Bazinga” which actually had only a picture of Sheldon Cooper from Big Bang Theory and one button, which, when pressed, outputed the sound “BAZINGA!”. This app was rejected the first time it was submitted because according to the tester it had not provided any value. Well that might be true for monetary value, yet the entertainment value is huge, at least for 5 to 10 seconds. So, my guess would be alright. But a developer doesn’t have to worry about these kind of things. Everything is negiotiable with the testers and you can prove your point – explain the cultural background, the entertainment purposes, etc.
So all in all, it was a really fun and creative day which inspired for some new ideas and will definetely result in an app in few weeks time. Microsoft is starting again to be the cool company in a new way which helps developers across the globe build the business around its architectural solutions, products and services. It even helped me already when my Windows 8 had some problems running on my Macbook, they lent me a ASUS tab which was a strange way to build apps, but definetely something every developer should try.
Government cloud
Today I was visiting one of our companies clients, meeting people – users of our software and mostly discusing usability issues.
There are a bunch of UX issues, people seeing too much or too little information, doing repetitive, not automated tasks andor simply clicking too much to achieve very little. This product is quite new indeed and has to meet a lot of different perspectives and requirements.
Putting aside the bad things we can surely take pride in our cloudy way of technology, which basically lets us solve the problems in multiple different approaches. Everything is decoupled into single (or at least narrow scope) responsibility WCF services so we have the option to redeploy software per service. That also means that if one service is down, unstable or simply written by monkeys, only the part of solution is doomed. Yet, if there are problems in the mission-critical services (read: workflow service, responsible for workflow execution) we are all still in big big trouble and hot fix procedure is kicked in (developers working overtime, all kinds of madness).
Our repository is not based on hadoop or anything so nice and open-sourcy, instead a service is dedicated to that problem. It handles the repository requests and offloads the services into one of two different targets – SQL database or file system. File system can be connected with shares or database can be replicated, so we don’t have any performance or scalability issues.
Aside from the actual backbones of our cloud we have quite flexible front-end which is based on ASP.NET MVC framework and really gives the possibility to make great impact in small amount of time and deploy new features daily. It is a lightweight frontend for us – though it often goes into something much more like OCR’ing images, distributed cache transactions, report generation, etc. Still most of the work is done with Javascript. We are currently looking into knockout.js to rewrite most of the spaghetis in it.
All of this infrastructure would be nonsense, huge pile of pointless technology if it would not redefine the way our users are working. It gives the opportunity to make government organizations effective in a way no other solutions would make possible. There is a different database for every organizational unit to implement accounting, labour payments, staff control, document processes, subordination, tasking and whatever else there is going on in that unit – even for example accounting of payments made by parents for kindergarten. These database are then consolidated into a business intelligence cubes for analytical data processing, at any time we can now any little number that concerns us – how much we spent on fuel this day last year, how many invoices were payed from this company, how many documents are now overdue and where they are stuck at. So while we see government work as mostly inefficient bureaucracy, paper pushing and mystified processes, it is all being put in place, according to the law and mostly common sense – not exactly copying what people do in paper, but transfering and optimizing these processes. At first a lot of people were rejecting these changes, these new winds and the discomfort of new experiences in their life. But even the coldest hardest clerk now realize that this is for the best and we are going on the right path.
What really here matters for us, people with technical responsibilities, is to take note, that no technology is itself meaningful and great if it does not serve meaningful and great purpose. You can have IBM bladecenter servers, running cutting-edge, straight-out-of-Silicon-Valley technologies, built with newest cloud development tools and deployed on Google apps engine or Windows Azure. But if no one uses it and you are not making impact by solving peoples problems – it’s all garbage.
Systematic approach to performance tuning in the cloud: part 1
In the next month I’ll try to provide my approach to performance tuning in cloud applications, and this is my first post about the web applications.
—
There comes a time in every developers life when you are presented with a task: this system, or a part of it sucks on performance. Well what you are waiting for? Go fix it.
After you’re done crying andor beating your head against the wall, you should ask yourself – what should I do first.
Well first of all, you have to decide on the process, the user story, which is not performing great. So for example: as a user, I upload a document to the system and save the document profile. Not a complex one, but we have a user working with a web frontend, that creates a document profile (a descriptory system entity) with a file. Having worked in cloud architecture we know, that here we a have a running web instance, connected to services of some sort, a data source of some sort and a repository of some sort. But we should get into that later.
Now that you know what the user is doing and what doesn’t perform, you need to decide on the acceptance criteria of performance. So this process is taking 5 minutes to the user to do. So what? Is that like, good? Or bad? (or ugly?) You need two accurate solid numbers: normal process execution time and acceptable process execution time. Let’s say for the normal we have 1 minute and for the acceptable – 2 minutes. That means, that you are opting for the 1 minute time max as a developer and you have a buffer for user mistakes, slow internet connections and so on. Basically when you establish your goal, you are ready to continue.
Then comes the fun part – finding the bottleneck. In standart monolithic systems, that have server-client infrastructure and are not web based, it’s very easy to find it. Either it’s the client, or server – and most of the time the server. Now you have a cloud here, so your infrastructure might look something like this:
- Local browser app (a lot of code in JavaScript, JavaScript databases, message handlers, asynchronous processors, updaters, etc.)
- Web frontend – small frontend for handling request from the client side, it could be either PHP, MVC3, Ruby, whatever. Basically it consumes the requests sent from the browser and returns data from services, sends messages to services buses and returns instant result. There is no heavy logic here – templating, rendering different layouts, all common things that every web platform has.
- Services – now here’s the big stuff going. Huge volumes of data processing, heavy logic, yet, also a lot of simple methods – search, create, update, delete (SCRUD) is somewhere in this layer too.
- Repository – that’s another service but solely dedicated to storing data, might be Hadoop for example.
- Distributed cache – a component handling all your cached data across the cloud.
- Data storage – well databases, obviously.
More or less, every cloud infrastructure has these components in some way. So which one to look at when performance problems arise?
Every. Single. One. Though, my common practice is as follows:
If data retrieval of some sort which is involving data storage is not performing, I turn up the database profiler and see if the problem is there. About 50% of the time, that’s exactly the case. Crappy views, big joins, large datasets, etc. So you save a lot of time and get to the root cause quite fast. And if not – you will have to dig in from the top. About that – in the following posts.
